Заказчик

ООО «Сонда Про»
Сонда занимается разработкой и внедрением биометрических систем идентификации с 1991 года. Компания является одним из лидеров в области биометрических технологий.
Дисклеймер: Решаемая нами задача находится под NDA и мы не можем в полной мере показать данные на которых обучалась нейросеть, а также подробно описать архитектуру нейросети.
Введение и решаемая задача
Заказчик поставил перед нами следующую задачу: спроектировать и обучить нейросеть которая сможет определять одинаковые отпечатки пальцев.
Идеальным решением было бы обучить нейросеть, которая на выходе возвращает вектор свёртку, описывающий отпечаток вне зависимости от того он как сделан. Этот вектор свёртку можно трактовать как некоторую хэш сумму отпечатка.
Но данному варианту не суждено было быть реализованным и дальше вы поймёте почему мы пришли к немного другому решению.
Анализ данных
Заказчик предоставил нам несколько наборов данных, в которых было разное количество отпечатков. Отпечатки были представлены в бинарном формате с разделением на отпечаток (рис. 1.а), файл маски (рис. 1.б) и файл с особыми точками. В данной работе мы решили сконцентрироваться на изображениях отпечатков пальцев.
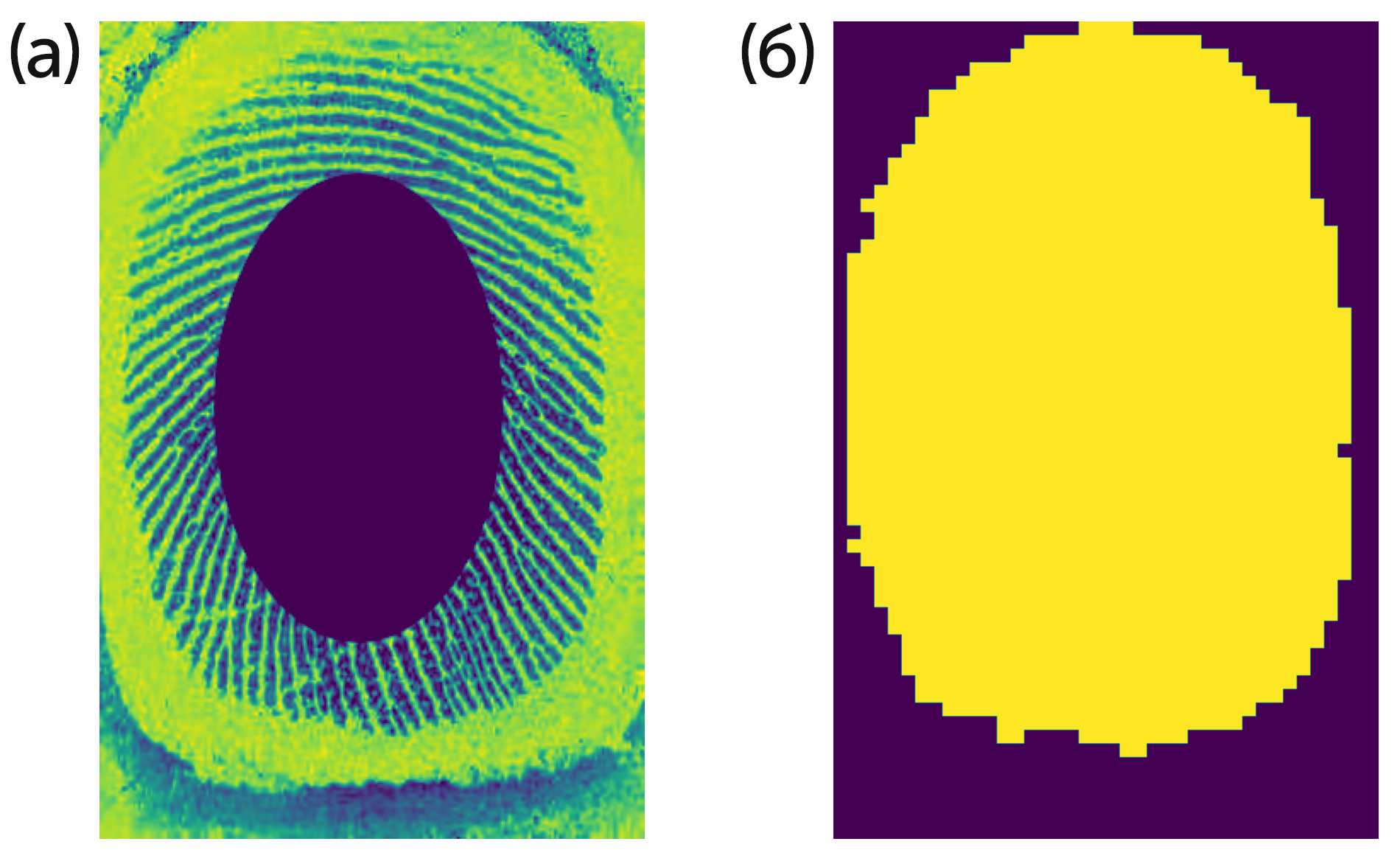
Рисунок 1: Входное изображение (а) и маска (б)
В ходе подготовки данных по очистке были испробованы разные методы бинаризации изображений (рис. 2.a), где варьировались параметры отсечения и алгоритм, но из-за вида входных данных многие не давали приемлемого результата. Основной проблема – сливающиеся папиллярный узор. По итогу мы остановились на использовании адаптивной алгоритма бинаризации c использованием метрики mean (рис. 2.б), который, по нашему мнению, был лучший из всех опробованных нами методов.
Если вам интересно, то со сравнением методов бинаризации изображений можно ознакомится на по ссылке.

Рисунок 2: Обычная (а) и адаптивная бинаризация (б)
Первый вариант
После того как мы разобрались с данными, то перешли к этапу проектирования архитектуры нейросети. В качестве первого варианта мы выбрали автоэнкодер (см. рисунок 3).
Мы решили реализовать так называемый Binary Autoencoder. Подробнее с ним можно ознакомится по ссылке. То есть мы рассчитывали что скрытый слой (latency layer) (слой z на рисунке 3) автоэнкодера будем выступать в роли хэша входного отпечатка, но всё оказалось не так просто, но об этом далее.
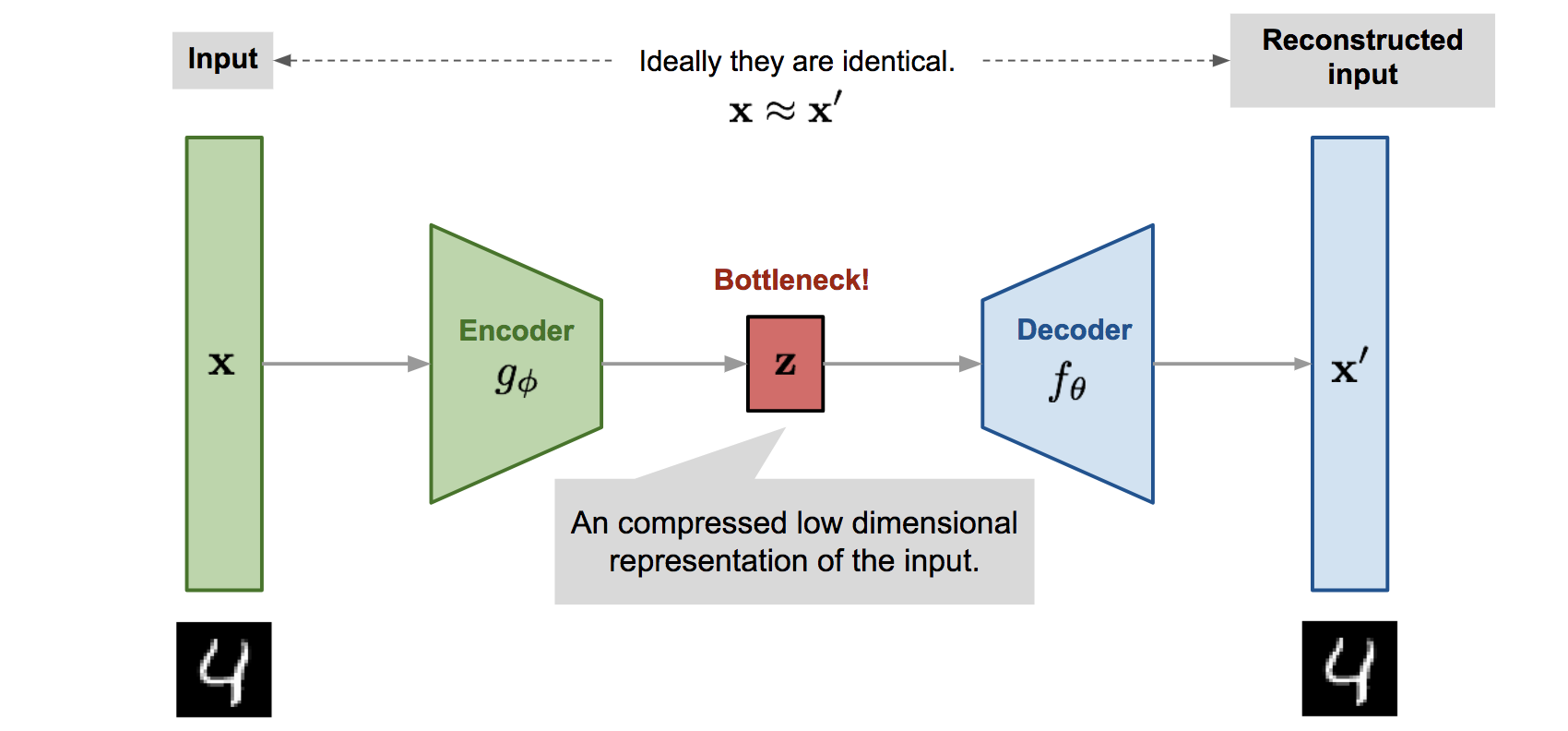
Рисунок 3: Архитектура автоэнкодера.
Обучить автоэнкодер довольно просто, по сравнению с другими архитектурами. Сначала возьмём данные и разделим на две выборки: данные для обучения и данные для валидации. Разделение мы обычно делаем в следующей пропорции 90% на обучение и 10% на валидацию. Для разделения удобно использовать функцию из библиотеки scikit-learn.
В качестве оптимизатора для модели используем алгоритм Адама, а в качестве функции потерь BinaryCrossentropy. Переходя к самим моделям энкодера и декодера, то в качестве слоёв используем Conv2D и MaxPooling2D, так как построение на основе только слоя Dense не имеет смысла из-за большого количества связей между слоями у больших входных изображений.
Теперь только остаётся обучить в течении 100-200 эпох пока не выйдем на плато по точности модели. На рисунке 4 представлен график обучения автоэнкодера, который мы обучали в течении 100 эпох.
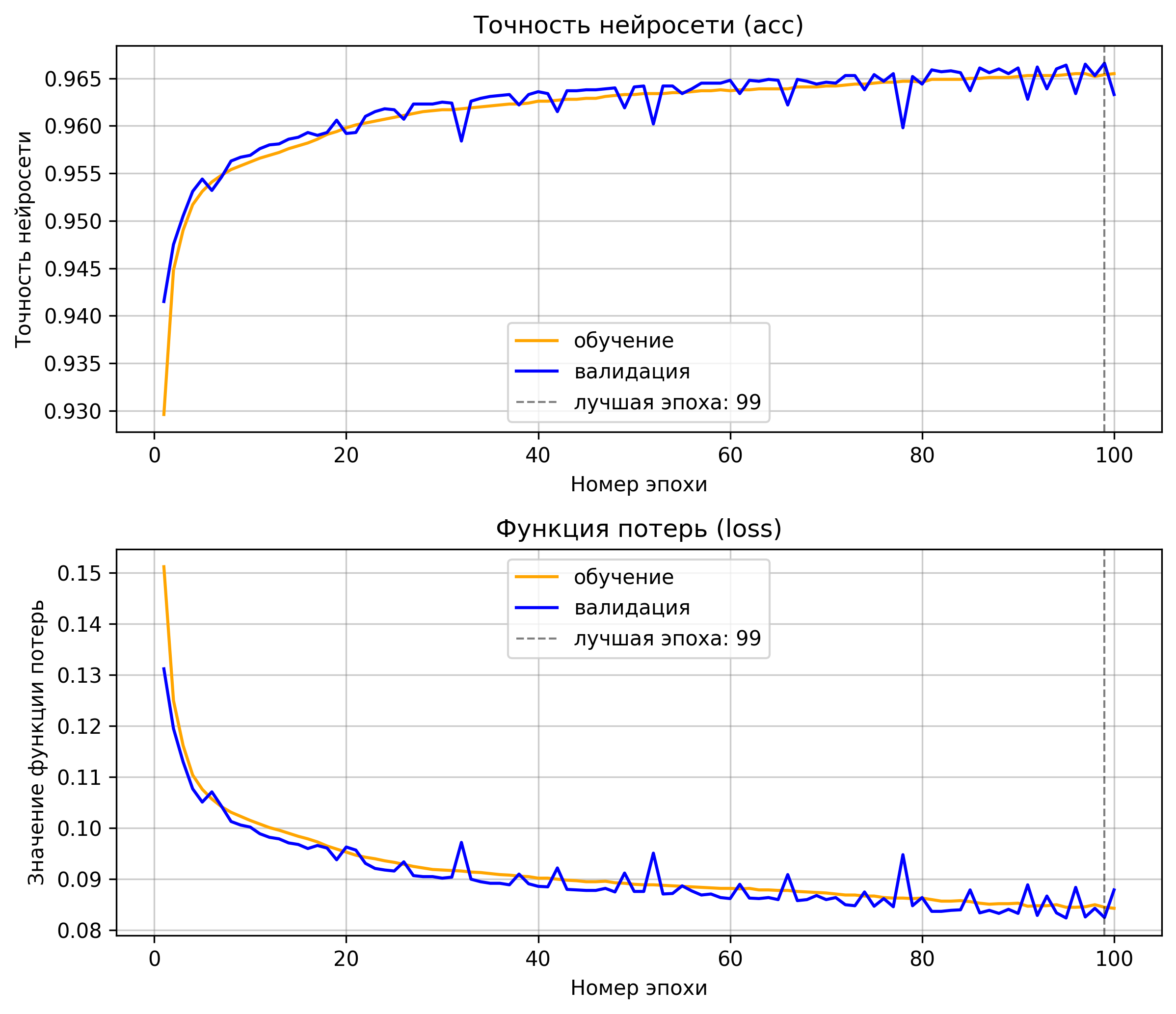
Рисунок 4: График обучения автоэнкодера.
Результатом обучения автоэнкодера получили точность в 96%. На изображении 5.б можно видеть как автоэнкодер очень хорошо справился с восстановлением исходного изображения.

Рисунок 5: Входное (а), восстановленное (б) и восстановленное округлённое (в) изображения.
В качестве метрики сравнения выходных векторов (читай как скрытый слой) мы решили использовать несколько метрик:
- расстояние Хэмминга;
- расстояние Индела;
- расстояние Левенштейна.
Для этого в качестве слоя активации была использована сигмойда в выходном слое модели энкодера. После этого выходной вектор энкодера нужно было бинаризовать и полученный результат использовать для сравнения.
Но, увы, данный поход не дал успеха, так как не было возможно отделить два класса изображений. На рисунке 6 можете увидеть, что невозможно выделить границу отсечения, когда отпечаток можно отнести к классу «отпечатки совпадают». По оси X представлены расстояния Хэмминга, а ось Y выбрана в качестве класса – совпадает = 1, а не совпадает = 0.
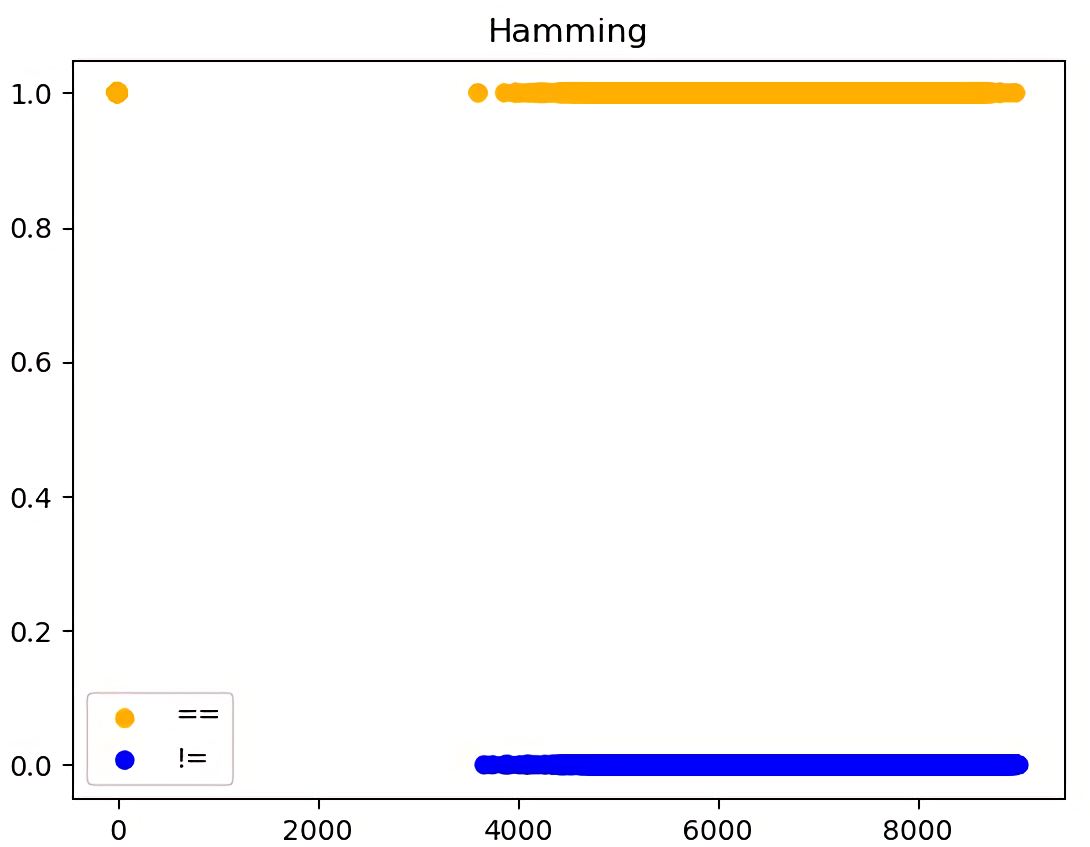
Рисунок 6: Расчёт расстояния Хэмминга для отпечатков. Желтый – отпечатки совпадают, синий – отпечатки не совпадают.
После данного сравнения мы решили посмотреть что из себя представляет скрытый слой и получили что автоэнкодер просто уменьшал входное изображение вместо извлечения фичей из данных отпечатка.
На этом мы решили остановить эксперименты с автоэнкодером и идти искать другую архитектуру для данной задачи.
Внезапное озарение
После долгих попыток получить что-то внятное из автоэнкодера мы решили сконструировать самую простую архитектуру. Оказалось, что самое простое решение данной задачи является самым лучшим.
Первая модель (coder) будет заниматься кодированием входного изображения в некоторое промежуточное состояние. Если быть точным, то это просто набор из нескольких свёрток которые уменьшают входное изображение до вектора 30x20.
Вторая же модель (predictor) будет заниматься сравнением векторов свёрток между собой и выносить вердикт – схожи два отпечатка или нет.
Результирующая модель (base) просто объединяет в себе обе. Это было сделано для удобства обучения. Вообще мы сконструировали модели таким образом чтобы их можно было использовать по отдельности.
Схематично архитектура полученной нейросети представлена на рисунке 7.

Рисунок 7: Схематичное представление архитектуры нейросети.
Результаты
В качестве результата работы нейросети можно получить результирующий вектор после модели coder, который дальше может быть использован для сравнения с другим вектором (через модель predictor) или помещён в базу данных. Пример такого вектора представлен на рисунке 8.

Рисунок 8: Выходной вектор (30x20) после модели coder (изображение увеличено)
В ходе обучения были достигнуты следующие показатели, представленные в таблице 1, а также на рисунке 9. Проверка производилась на выборке из 20 тыс. элементов, где половина принадлежала к классу «отпечатки совпадают», а вторая к «отпечатки не совпадают».
Метрика
Значение
0.9364
0.9288
0.9431
0.9359
Таблица 1: Метрики оценки точности обученной модели.
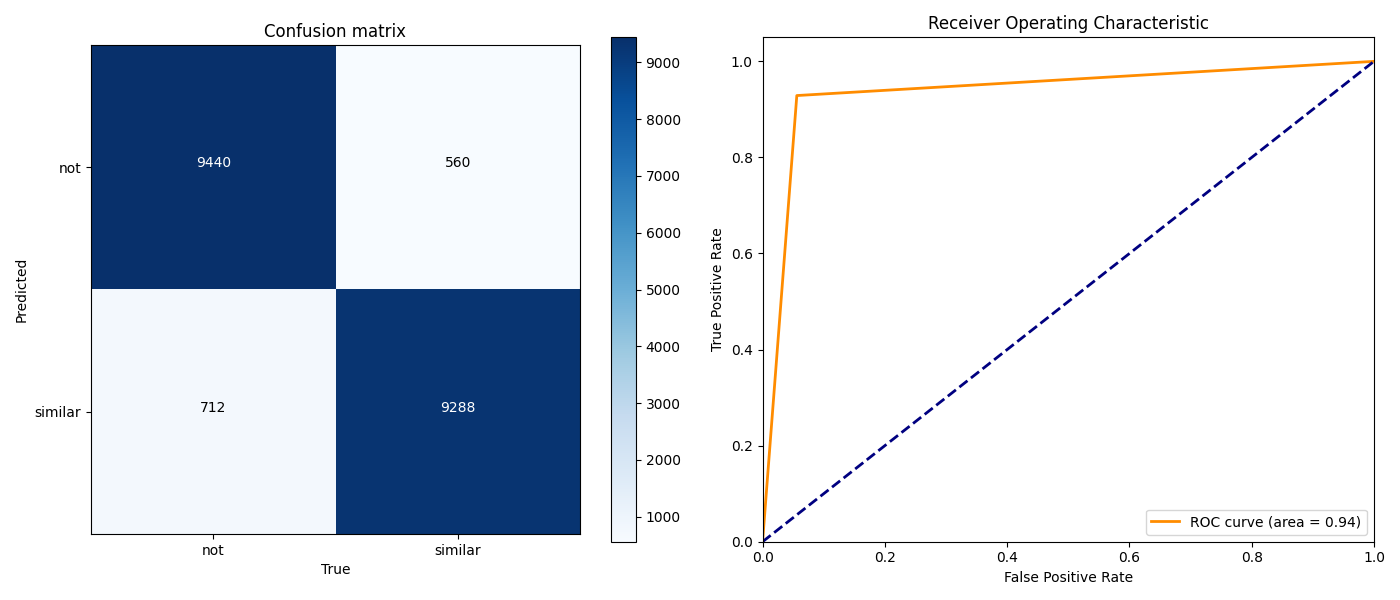
Рисунок 9. Матрица ошибок и ROC кривая.
Заключение
Разработка нейросетей — это всегда интересный и вариативный процесс, и данный проект не является исключением. Работа с биометрией это всегда вызов команде, и наши инженеры по машинному обучению не только применили уже накопленные знания, но расширили свою экспертизу за счет примененных в проекте подходов. Как и прежде, компания МСТ готова решать самые нестандартные задачи и предлагать своим клиентам высокое качество разработки нейросетей и программных продуктов.
Отзыв клиента

В июле 2019 года компания ООО «Аэро-Трейд» искала подрядчика для выполнения работ по внедрению системы безналичной оплаты товаров самолетах авиакомпании «AZUR air». После тщательного изучения рынка, мы решили обратиться для реализации данного проекта в компанию ООО «МСТ Компани». Основной задачей было обеспечить каждый борт авиакомпании «AZUR air» терминалом, который сможет принимать платежи не только на земле, но и во время полёта.
В течении всего времени нашего сотрудничества, специалисты ООО «МСТ Компани» продемонстрировали отличные профессиональные навыки при подготовке проекта, и разработке документации. В результате мы получили гибкое и надёжное решение, которое удовлетворяет нашим требованиям.
По итогам работы с компанией ООО «МСТ Компани» хочется отметить соблюдение принципов делового партнерства, а также четкое соблюдение сроков работ и выполнение взятых на себя обязательств. ООО «Аэро-Трейд» выражает благодарность специалистам компании за проделанную работу в рамках внедрения системы безналичной оплаты на самолетах авиакомпании «AZUR air». И рекомендует компанию ООО «МСТ Компани» как надёжного партнёра в области платёжных решений.