
15 июля 2020
Сейчас наверно даже ленивый не слышал про ChatGPT. Модель так сильно выстрелила, что многие уже предрешают смерть многим профессиям. Почему же ChatGPT так сильно завирусился? Думаю на это есть несколько причин.
Нейросеть умеет в контекст – ранее используемые модели довольно быстро его теряли после нескольких обращений. Да и пользователь всегда может попросить бота уточнить ответ, резюмировать текст или объяснить то, что тот не понимает. Короче ChatGPT может всё то же, что и обычный человек, да и даже больше.

Вообще у ChatGPT был и предшественник, а именно модель InstructGPT. Её представляли ранее, но такого же успеха в сети она не сыскала.
А всё из-за того как была обучена нейросеть. Если ChatGPT пытается уменьшить количество вредных и вводящих в заблуждение ответов, а также использует дополнительную информацию для формирования ответа, то InstructGPT действует напрямую и принимает всё за чистую монету.
Но не будем про InstructGPT, а перейдём к виновнику торжества.
О технологии
Вообще рассматривая такие интересные вещи невольно тянет заглянуть «под капот» к такой сети. Но, увы, OpenAI пока даёт только доступ к API и то, только ограниченный.
Поэтому мы зайдём с другой стороны и немного поговорим про архитектурные элементы, что доступны нам из многочисленных источников.
Вообще в основе ChatGPT лежит много интересных технологий, но думаю особое внимание стоит заострить на паре из них:
- Reinforcement Learning from Human Feedback (RLHF).
- Архитектура Transformer.
Если же вы заинтересованы в большем количестве деталей, то стоит обратить внимание на статью GPT для чайников: от токенизации до файнтюнинга.
Теперь переходя к RLHF и особо не углубляясь в дебри машинного обучения можно сказать что это просто обучения с обратной связью от человека. Но это слишком поверхностное описание этой технологии, да и особо непонятно что и как.
Давайте рассмотрим этот момент поподробнее на простом примере.
Допустим у нас есть модель, которая усвоила уже базовые понятия из языка, но пока формирует ответа очень криво, с точки зрения носителя языка. Предложения могут быть вполне корректные по структуру, но никто так не говорит.
Бот: Превед Медвед!
Поэтому человек даёт фидбек о том, что так не говорят и даёт более подходящую языковую конструкцию. Нейросеть получает этот фидбек и вносит корректировки в свою внутреннюю модель.
Бот: Превед Медвед!
Человек: Так говорили в интернете в 2007! Надо говорить привет или здравствуйте!
Бот: Здравствуй Медвед!
Человек: Уже лучше.
Так продолжается до того момента, пока нейросеть не достигнет определённой планки в качестве ответов.
Вообще все там конечно всё сложнее, но для общего понимания достаточно. Архитектурно это выглядит вот так:
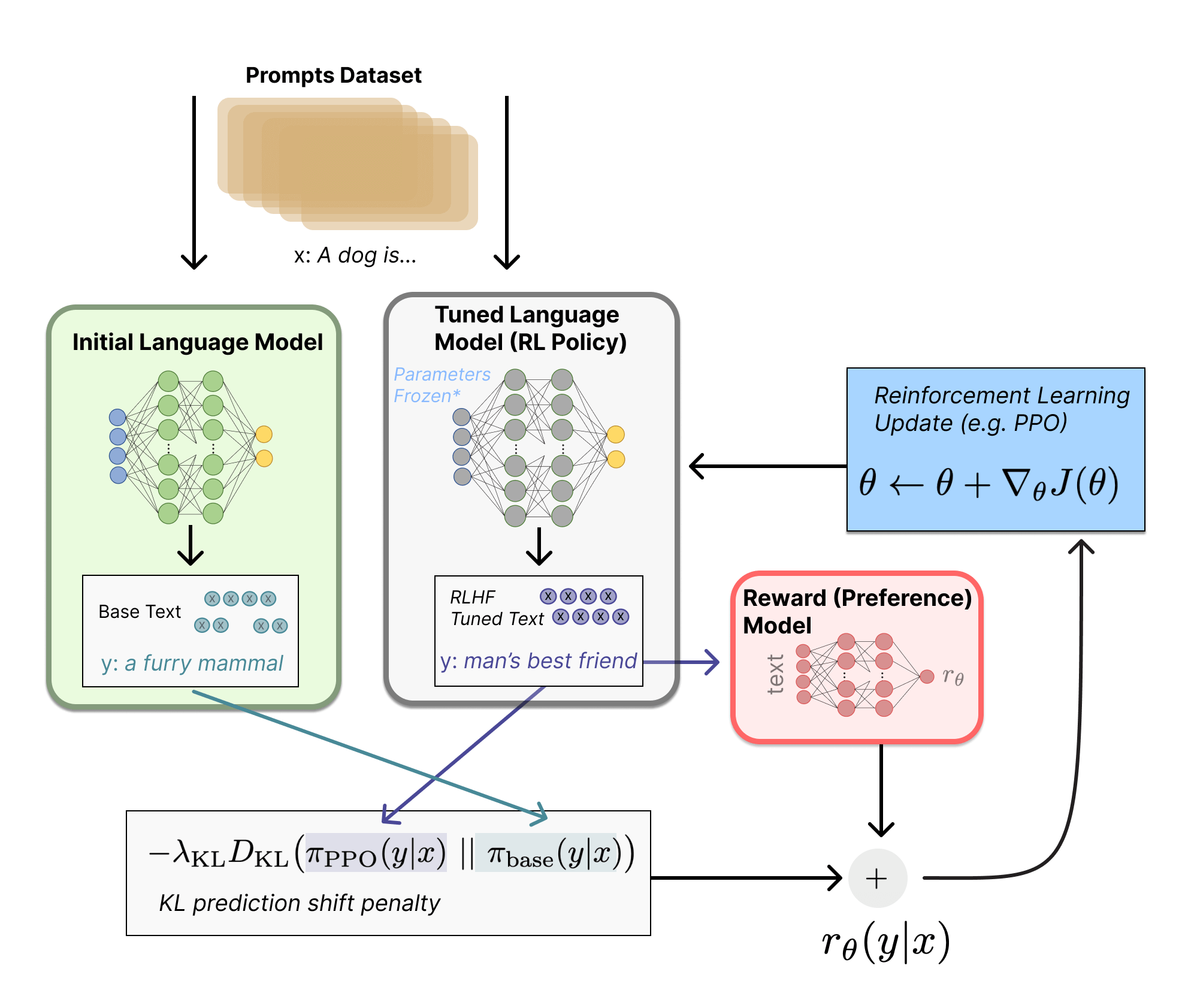
Грубо говоря это и есть суть метода RLHF, если пытаться рассказать её по простому. Если нужно более подробное описание со всеми этапами, то стоит обратиться к статьям Illustrating Reinforcement Learning from Human Feedback (RLHF) и Learning from Human Preferences.
С RLHF закончим на этом и перейдём к трансформеру.
Давайте сначала немного копнём в историю архитектуры. Согласно интернету его представила команда Google Brain в 2017 году, как замена архитектуры рекуррентной нейросети (RNN).
Тут стоит пояснить что до этого момента для работы с текстом использовались RNN на базе LSTM (сеть долгой краткосрочной памяти), у которых был очень большой недостаток — им необходимо было обрабатывать текст последовательно, что сильно тормозило скорость обучения, да и были многие другие проблемы из-за которых напридумывали множество вариантов таких сетей.
Теперь же, имея новую архитектуру мы лишены главного недостатка прошлых архитектур.
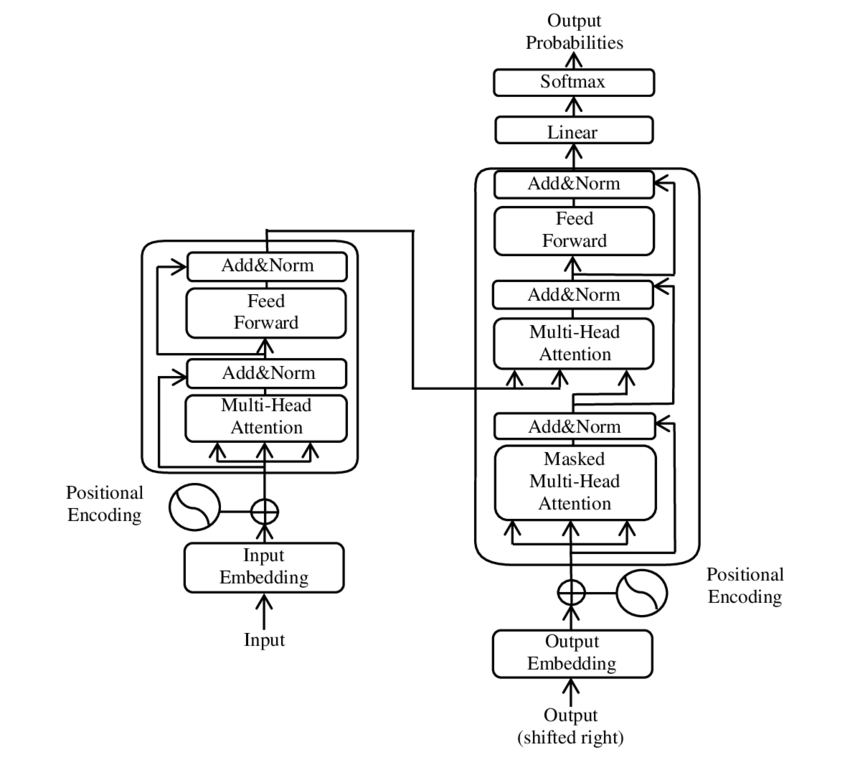
Конечно тут стоило бы ещё написать про механизм внимания трансформера и более подробно углубиться в матчасть, но это выходи за рамки «пары слов…». Любопытные же всегда могут углубиться в теорию и начать можно со статьи в википедии Transformer (machine learning model).
Проблемы
Про архитектурные моменты «поговорили» и теперь уже стоит обсудить проблемы ChatGPT, так как без них не бывает новых технологий!
Одна из проблем модели — её ограничения на этику. Кто-то скажет что эти ограничения обязательны, но это очень спорный вопрос.
Вообще ChatGPT можешь легко дать некорректный ответ, который только будет похож на корректный. Это большая проблема, которую не так просто решить, но если проводить параллель с людьми, то и мы не всегда правы.
Стоит ещё упомянуть что модель очень чувствительна к входному тексту. То есть на одно предложение она может не знать ответ, но немного изменив его, не поменяв сути и модель уже легко отвечает на заданный вопрос.
Человек: Что такое НЛП?
Бот: Амм... не знаю что вы имеете ввиду?
Человек: Что такое Natural Language Processing?
Бот: Садись человек поудобнее и слушай мой рассказ!
Хоть OpenAI и пытались защититься от «неподабающей» лексики в вопросах и ответах, но всегда могут проскочить «вредные» советы. Тут только дообучать и получать фидбек от пользователей.
Ещё одной проблемой ChatGPT является человеческий надзор за её обучением. Тут чисто из-за того что люди не объективны в своих суждениях и поэтому модель может быть предвзятой в той или иной мере. Хотя с увеличением количества фидбэка всё может стать лучше, хотя все мы ещё помним историю Tay.
Кто есть помимо ChatGPT?
Вообще кроме ChatGPT есть и другие разработки, но по уровню хайпа они сильно не дотягивают.
Тут вообщее кратко получиться, так как мало у кого готовы ответы на ChatGPT, но вообще можно выделить пару, по которым хоть что-то есть вменяемое в медиапространстве:
Проблема этих сетей в том, что к ним сейчас почти никак не получить доступ.
Недавно была пререгистрация на тесты LaMDA тут, но не думаю что будет много везунчиков, которые смогут пощупать модель.
Про YaLM 2.0 версии вообще мало чего известно. Только то что Яндекс будет внедрять её в поисковой движок и она находиться в активной разработке. Но с другой стороны они выложили в свободный доступ первую версию этой сети. Так что можно ожидать что вторую можно будет в отдалённом будущем пощупать.
Про другие нейросети пока только обещания. Из последнего то, что LAION хочет сделать доступный чат бот, похожий на ChatGPT, который можно будет запустить на обычном ПК, по аналогии с Stable Diffusion.
Вообще думаю стоит ожидать бота от Meta, так как до этого они выкладывала свою OPT, хотя у них сейчас других проблем навалом.

Ну, посмотрим что будет.
Что нас ждёт?
Как вышел ChatGPT, то многие сразу сильно напряглись. Никто же не хочет чтобы у него забрали работу.
Тут надо больше думать про то, что придётся адаптироваться к новым технологиям, а не сидеть и бояться когда тебя заменят бездушной машиной.

Ведь когда появились MidJourney, Stable Diffusion, DALL-E и многие другие люди не побежали сразу заменять всех художников на нейросети.
Конечно паника среди художников была большая, да и она всё ещё не затихает, даже иск относительно недавно подали на нейросети.
Но всегда найдутся более прозорливые художники, которые уже используют в работе нейросети и не парятся по поводу того, что у них заберут работу.
Как пример, некоторые стали использовать Stable Diffusion для генерации референсов, а сообщество Blender вообще пошло дальше и запили аддон для использования в программе AI-Render и dream textures.
Тут стоит напомнить что время циклично, и когда только появлялась фотография у художников так же сильно «подпекало». И как мы может судить — художники не вымерли, хоть и потребность на картины и упала.
Так что…

Если хотите ещё почитать немного мыслей по этому поводу, то стоит обратиться к статье Вастрика: ChatGPT. Когда нас уже заменят нейросетями?, а также почитать статью в Хакере: Художники против ИИ. Разбираемся с юридическим статусом творчества нейросетей.
Вместо выводов
Вообще вот такая движуха в стане машинного обучения должна только радовать человека, так как все эти технологии разрабатываются на облегчение нашей с вами работы, а не во вред.
Конечно не все это понимают или не хотят понимать, но прогресс это такая штука, которую не так уж и легко остановить.
Так что наслаждайтесь новыми крутыми технологиями и не парьтесь по мелочам!



